Hugging Face 新开源了一款 TTS 模型: Parler |
您所在的位置:网站首页 › python语音转文字 中文开源模型 › Hugging Face 新开源了一款 TTS 模型: Parler |
Hugging Face 新开源了一款 TTS 模型: Parler
|
大家好,我是xq👨🏻💻。今天要给大家介绍一款Hugging Face(抱脸)新开源的TTS模型:parler-tts,完全开源免费的一款TTS工具。 Parler-TTS 介绍Parler-TTS 是抱脸新开源的一种轻量级文本转语音 (TTS) 模型。  可以按照给定说话者的风格(性别、音调、说话风格等)生成高质量、听起来自然的语音。 与其他 TTS 模型相反,这款轻量级 TTS 模型将所有数据集、预处理、训练代码和权重来了个一次性大公开。 虽然没有像其它 TTS 工具一样,预置配音员模型、语速控制等功能。但可以让社区内的开发者们基于此模型开发出具备各场景特色或者更加强大的 TTS 模型,自由度非常高。 如今发布的第一个版本名为:Mini v0.1。是一个 600M 参数模型,经过 10.5K 小时 的音频数据训练。 据官方介绍,接下来将致力于将数据扩展到 50,000 小时,为 v1 模型做准备。 GitHub:https://github.com/huggingface/parler-tts[1] Parler-TTS 使用HuggingFace 也提供了mini版本Demo项目可以进行体验 (有条件的开发者也可以自行搭建,而且 Parler-TTS 只需一行代码即可安装。) 在线demo:https://huggingface.co/spaces/parler-tts/parler_tts_mini[2] 我们进入了Demo界面,回发现他只有 2个输入项,1个输出。 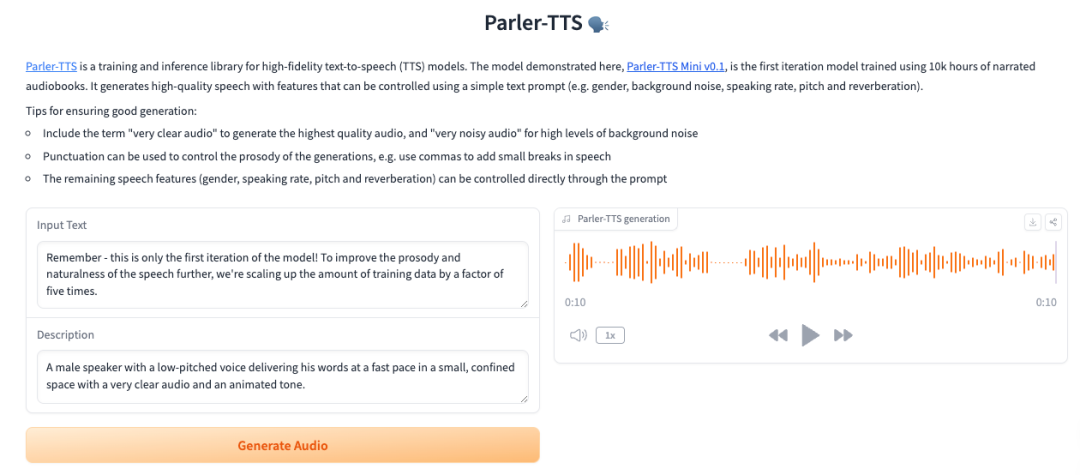 • Input Text:需要转语音的文本• Description:对于音频角色、场景、语调、音色等信息的描述,类似于Prompt。比如:一个声音低沉的男性演讲者,在一个狭小的空间里以快速的节奏说话,声音清晰,语调生动。• Parler-TTS generation:生成的音频文件(可试听、下载) • Input Text:需要转语音的文本• Description:对于音频角色、场景、语调、音色等信息的描述,类似于Prompt。比如:一个声音低沉的男性演讲者,在一个狭小的空间里以快速的节奏说话,声音清晰,语调生动。• Parler-TTS generation:生成的音频文件(可试听、下载)当然,如果想定制声音,也可以根据自己的数据集对该模型进行训练和微调。 总结Parler-TTS 是一款完全开源的 TTS 模型。自由度及创新性非常高,并且可以通过Prompt控制说话者的性别、音色、语调以及所处的场景(室内、室外、马路上、音乐厅等)。 不过对比其他TTS模型,上手的确难度大一些。对于玩过GPT、AI绘画的还是比较容易入手的。 期待v1版本带来更多更实用的功能与生成效果。 |
【本文地址】
今日新闻 |
推荐新闻 |